This website is outdated, please navigate to our new website: hanlab.mit.edu
Intelligent edge devices with rich sensors (e.g., billions of mobile phones and IoT devices) have been ubiquitous in our lives. Deploying artificial intelligence (AI) to these edge devices is attractive for many real-world applications: smart home, smart retail, smart manufacturing, autonomous driving, and more. However, state-of-the-art deep learning systems typically require tremendous amount of resources (e.g., memory, computation, data, AI experts), both for training and inference. This hinders the application powerful deep learning systems on edge devices.
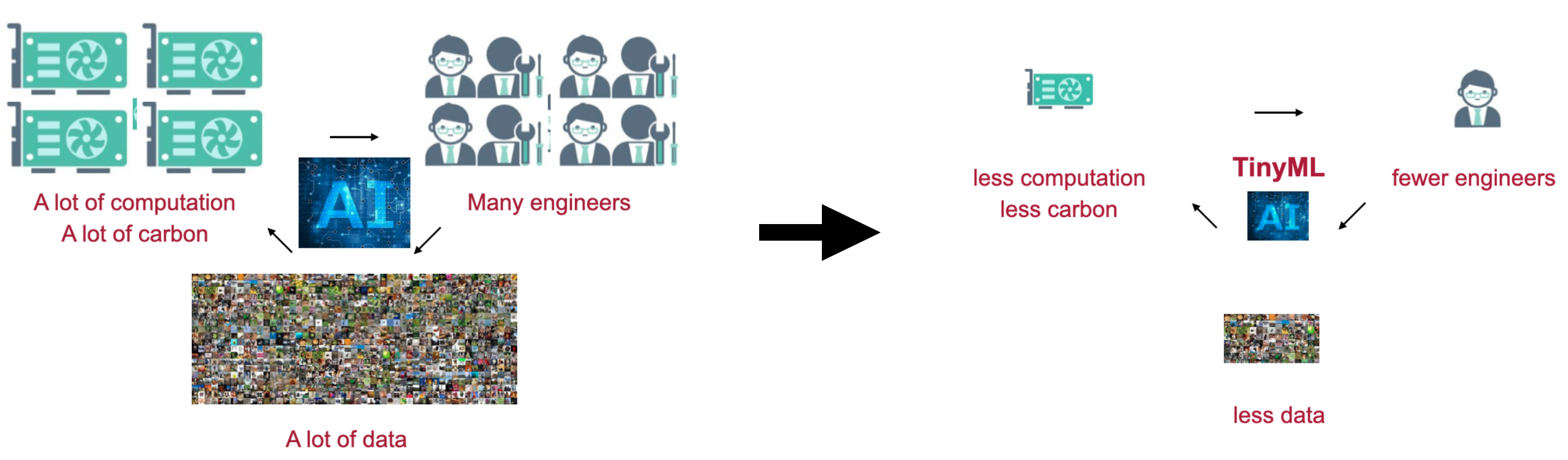
Our TinyML project aims to improve the efficiency of deep learning by requiring less computation, fewer engineers, and less data, from algorithm to hardware, from inference to training. We embrace the era of edge AI and AIoT.
Figure 1: We aim to improve the efficiency of deep learning AI systems, including computation efficiency, engineer enfficiency and data efficiency. Our research enables powerful artificial intelligence (AI) algorithms run more efficiently on low-power mobile devices.
Figure 2: TinyML enables powerful neural networks to run efficiently on various hardware platforms, from cloud AI, to mobile AI, and to AIoT.
We actively collaborate with industry partners on efficient AI, model compression and acceleration. Our research has influenced and landed in many industrial products: Intel OpenVino, Intel Neural Network Distiller, Apple Neural Engine, NVIDIA Sparse Tensor Core, AMD-Xilinx Vitis AI, Qualcomm AI Model Efficiency Toolkit (AIMET), Amazon AutoGluon, Facebook PyTorch, Microsoft NNI, SONY Neural Architecture Search Library, SONY Model Compression Toolkit, ADI MAX78000/MAX78002 Model Training and Synthesis Tool.
Efficient Deep Learning Algorithms
AutoML / Neural Architecture Search
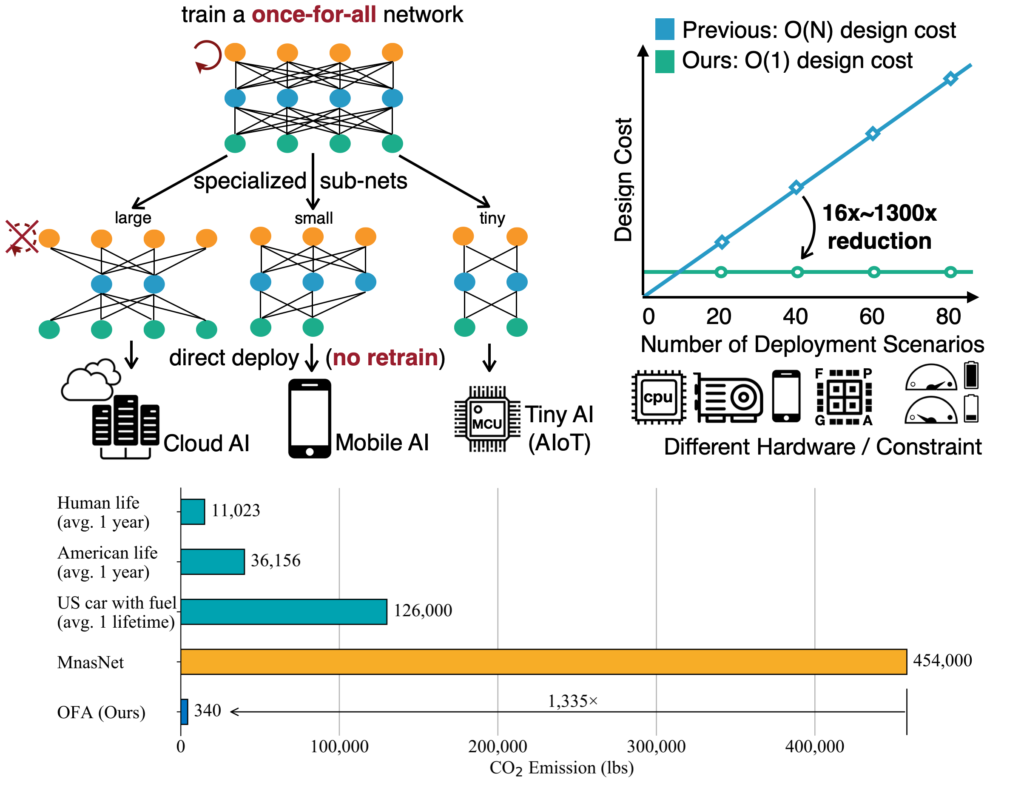
Once for All: Train One Network and Specialize it for Efficient Deployment ICLR’20 Once-for-all (OFA) network supports diverse architectural settings by decoupling training and search, to reduce the cost of efficient inference across many devices and resource constraints, especially on edge devices.
MCUNet: Tiny Deep Learning on IoT Devices NeurIPS’20 MCUNet is a framework that jointly designs the efficient neural architecture (TinyNAS) and the lightweight infer-ence engine (TinyEngine), enabling ImageNet-scale inference on microcontrollers.
ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware ICLR’19 ProxylessNAS can directly learn the architectures for large-scale target tasks and target hardware platforms. It addresses the high memory consumption issue of differentiable NAS and reduce the computational cost to the same level of regular training while still allowing a large candidate set.
Model Compression
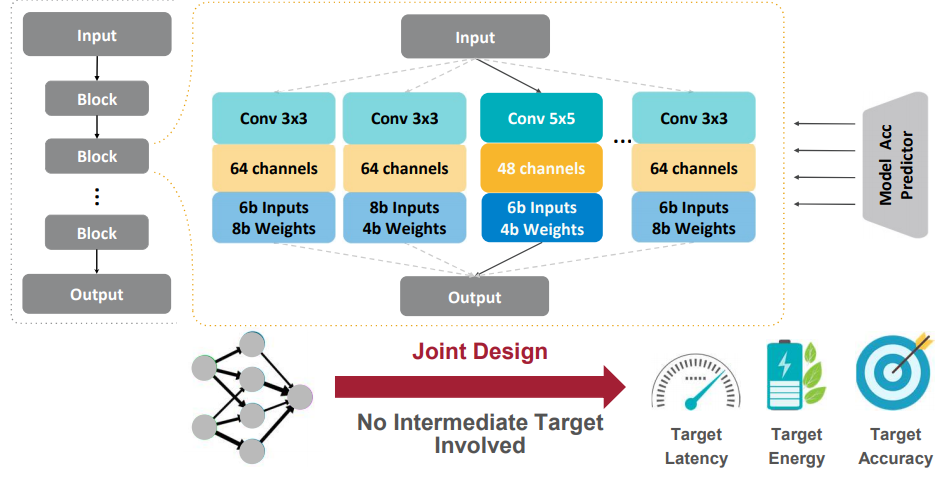
APQ: Joint Search for Network Architecture, Pruning and Quantization Policy CVPR’20 APQ jointly searches the neural architecture, pruning policy, and quantization policy. To handle the larger design space, APQ transfers the knowledge from a fullprecision (i.e., fp32) accuracy predictor to the quantization-aware (i.e., int8) accuracy predictor to improve the sample efficiency.
AMC: AutoML for Model Compression and Acceleration on Mobile Devices ECCV’18 AutoML for Model Compression (AMC) leverages reinforcement learning to provide the model compression policy. This learning-based compression policy outperforms conventional rule-based compression policy by having higher compression ratio, better preserving the accuracy and freeing human labor.
HAQ: Hardware-Aware Automated Quantization CVPR’19 Hardware-Aware Automated Quantization (HAQ) framework leverages the reinforcement learning to automatically determine the quantization policy, and takes the hardware accelerator’s feedback in the design loop.
Efficient Training
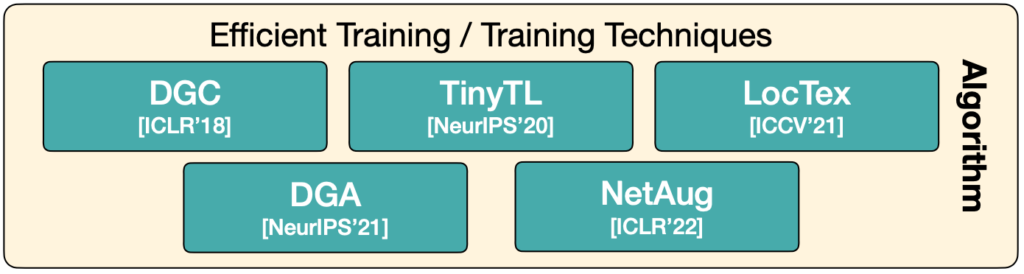
On Device Training under 256kB Memory NeurIPS’22 Conventional trainning is expensive in both memory and computation, thus mostly performed on the cloud server. We propose an algorithm-system co-design framework to make on-device training possible with only 256KB of memory, enabling on-device training on micro-controllers to adapt to new data collected from the sensors.
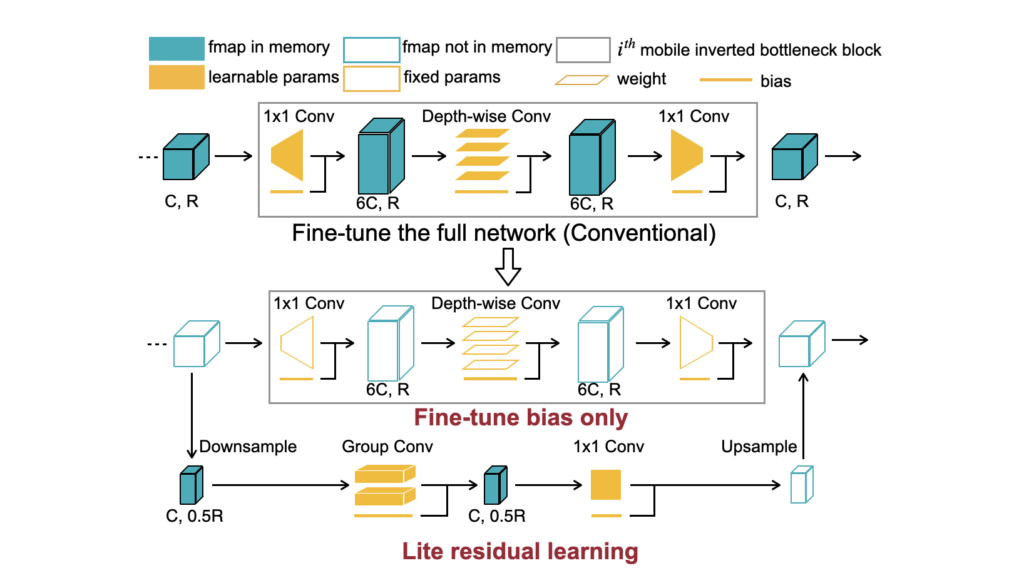
TinyTL: Reduce Memory, Not Parameters for Efficient On-Device Learning NeurIPS’20 Tiny-Transfer-Learning (TinyTL) provides memory-efficient on-device learning by freezing the weights while only learns the bias modules to get rid of the intermediate activations, and introducing the lite residual module to maintain the adaptation capacity.
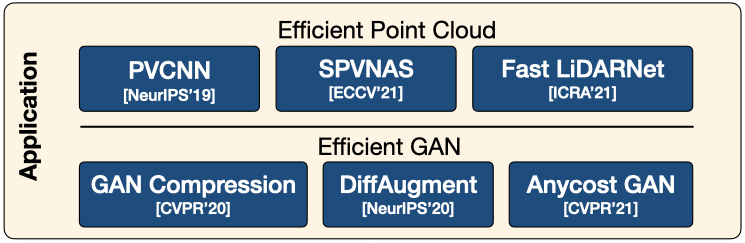
Point-Voxel CNN for Efficient 3D Deep Learning NeurIPS’19 Spotlight PVCNN represents the 3D data in points to reduce the memory consumption, while performing the convolutions in voxels to reduce the irregular, sparse data access and improve the locality.
Efficient and Robust LiDAR-Based End-to-End Navigation ICRA’21 Fast-LiDARNet achieves real-time performance on NVIDIA Jetson AGX Xavier. Together with Hybrid Evidential Fusion, it enables efficient and robust end-to-end LiDAR-based navigation (even in the case of occasional sensor failure).
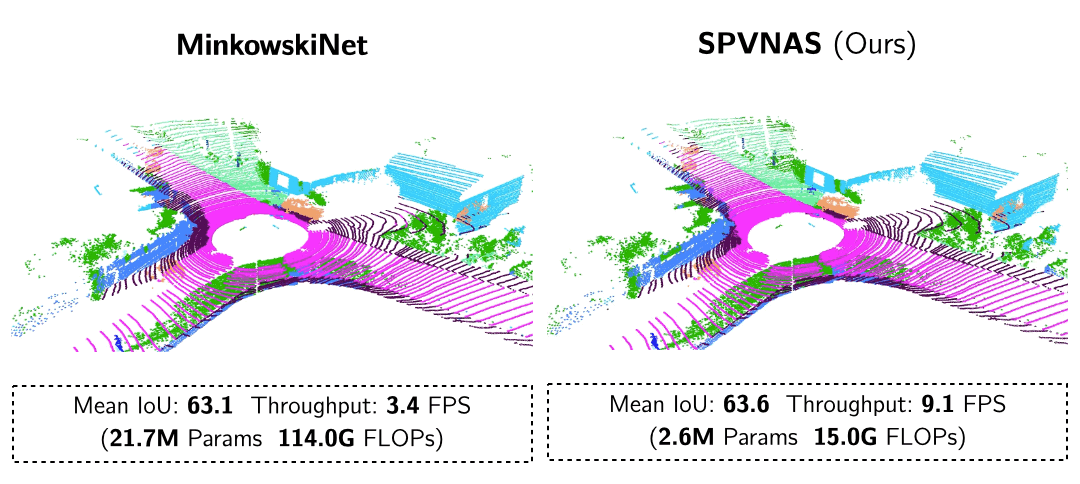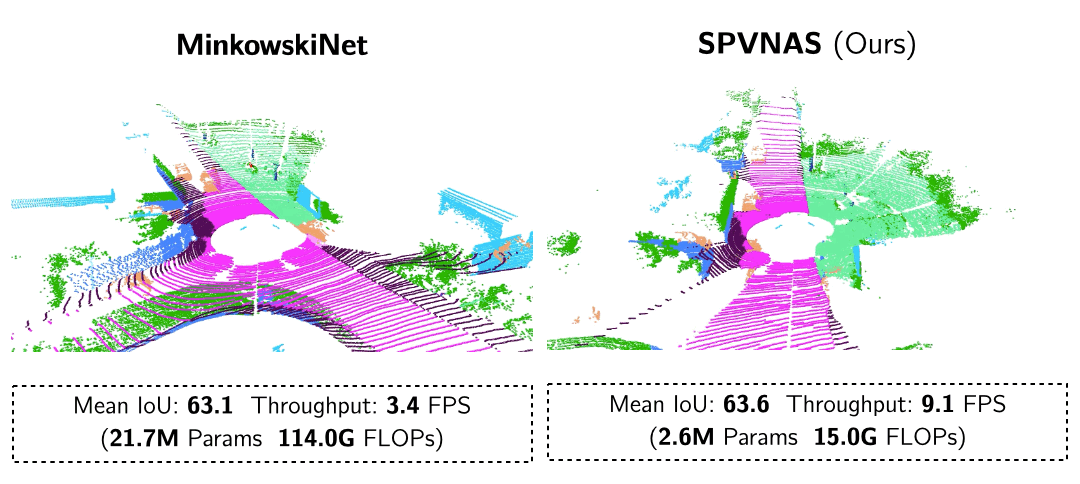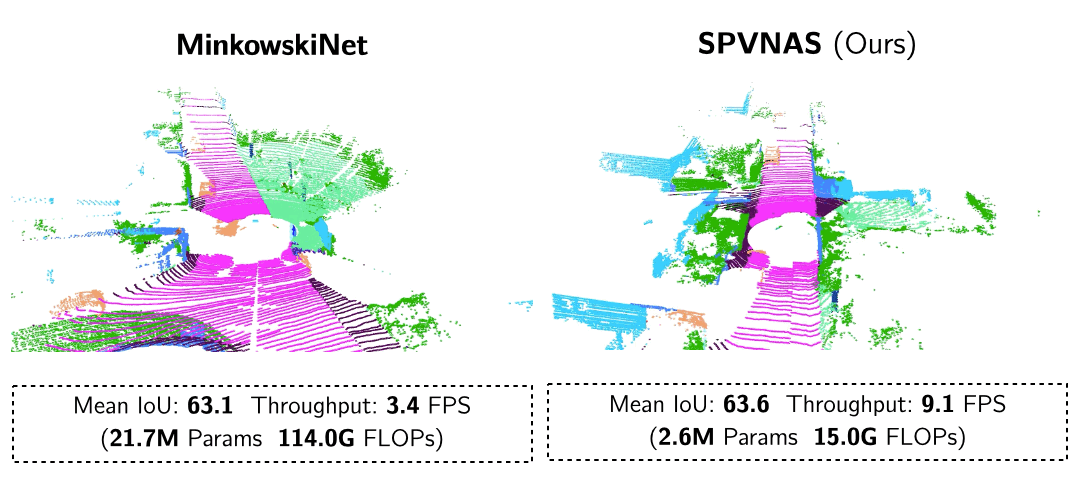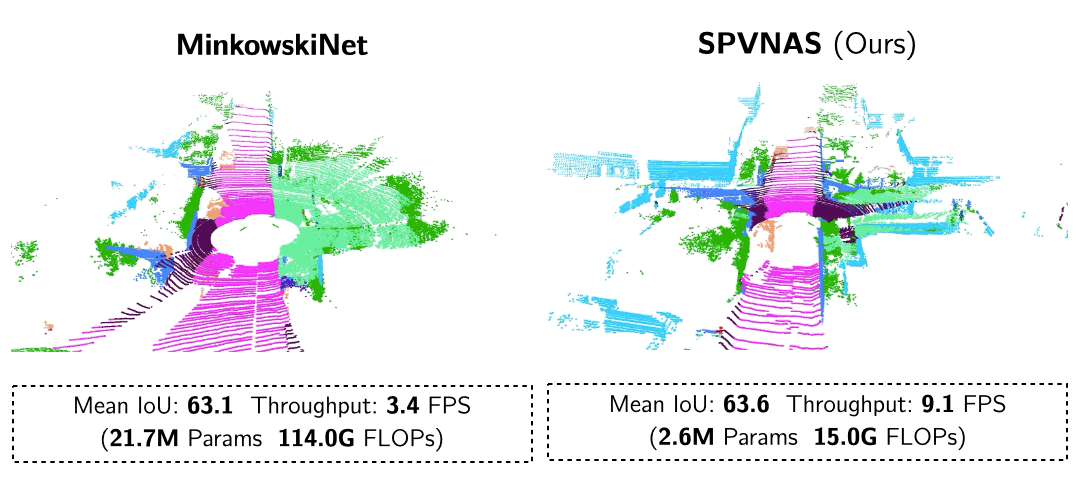
Searching Efficient 3D Architectures with Sparse Point-Voxel Convolution ECCV’20 SPVNAS enhances Point-Voxel Convolution in large-scale outdoor scenes with sparse convolutions. With 3D Neural Architecture Search (3D-NAS), it efficiently and effectively searches the optimal 3D neural network architecture under a given resource constraint.
BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation ICRA’23 BEVFusion unifies multi-modal features in the shared bird’s-eye view (BEV) representation space, which nicely preserves both geometric and semantic information. It establishes the new state of the art on nuScenes, achieving 1.3% higher mAP and NDS on 3D object detection and 13.6% higher mIoU on BEV map segmentation, with 1.9x lower computation cost.
Tiny GAN
Anycost GANs for Interactive Image Synthesis and Editing CVPR’21 For interactive natural image editing, Anycost GAN is trained to support elastic resolutions and channels for faster image generation at versatile speeds. Running subsets of the full generator produce outputs that are perceptually similar to the full generator, making them a good proxy for quick preview.
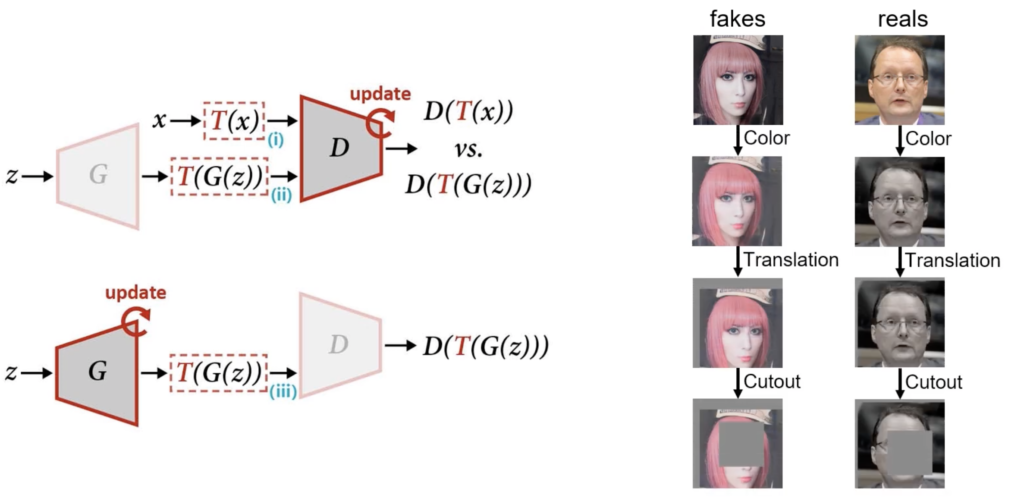
Differentiable Augmentation for Data-Efficient GAN Training NeurIPS’20 Differentiable Augmentation (DiffAugment) improves the data efficiency of GANs by imposing various types of differentiable augmentations on both real and fake samples, and effectively stabilizes training, and leads to better convergence.
Tiny NLP: Efficient Natural Language Processing
HAT Hardware-Aware Transformer NAS ACL’20 HAT NAS framework leverages the hardware feedback in the neural architecture search loop, providing a most suitable model for the target hardware platform.
Lite Transformer with Long-Short Range Attention ICLR’20 Lite Transformer facilitates deploying mobile NLP applications on edge devices. The key primitive is the Long-Short Range Attention (LSRA), where one group of heads specializes in the local context modeling (by convolution) while another group specializes in the long-distance relationship modeling (by attention).
MicroNet for Efficient Language Modeling JMLR’20 NLP Micronet experiments on weight pruning and quantization of lanauge models. It reduces the model size by more than 41x and won the champion of NeurIPS 2019 MicroNet efficient NLP challenge.
Tiny Video
TSM: Temporal Shift Module for Efficient Video Understanding ICCV’19 Temporal Shift Module (TSM) can achieve the performance of 3D CNN but maintain 2D CNN’s complexity, by shifting part of the channels along the temporal dimension and thus facilitating information exchanged among neighboring frames.
Efficient Deep Learning Systems
Approaches introduced above are top-down solutions for efficient deep learning processing, where performance gains come from algorithmic optimization. However, these theoretical benefits (e.g., FLOPs and model size) cannot be easily converted into real improvements in measured speedup and energy efficiency. Therefore, specialized software/hardware systems are required to bridge the gap. On the other hand, these specialized software/hardware systems open up a new design space orthogonal to the algorithm space, bringing opportunities for holistic optimization by jointly optimizing the algorithm and software/hardware systems.
Efficient Software Libraries
IOS: Inter-Operator Scheduler for CNN Acceleration MLSys’21 Beyond intra-operator parallelization in existing deep learning frameworks such as TVM, Inter-Operator Scheduler (IOS) automatically schedules multiple operators’ parallel execution through a novel dynamic programming algorithm.
TinyEngine: Efficient Deep Learning on MCUs NeurIPS’20 MCUNet is a framework that jointly designs the efficient neural architecture (TinyNAS) and the lightweight infer-ence engine (TinyEngine), enabling ImageNet-scale inference on microcontrollers.
TorchSparse: Efficient Point Clouds Inference Engine MLSys’22 TorchSparse is a high-performance computing library for efficient 3D sparse convolution. This library aims at accelerating sparse computation in 3D, in particular the Sparse Convolution operation.
Efficient Hardware
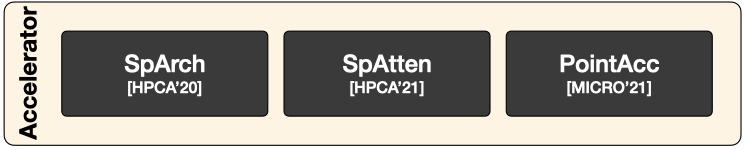
PointAcc: Efficient Point Cloud Accelerator MICRO’21 PointAcc is a novel point cloud deep learning accelerator. It introduces a configurable sorting-based mapping unit that efficiently supports diverse operations in point cloud networks. PointAcc further exploits simplified caching and layer fusion specialized for point cloud models, effectively reducing the DRAM access.
SpAtten: Efficient Natural Language Processing HPCA’21 SpAtten is an efficient algorithm-architecture co-design that leverages token sparsity, head sparsity, and quantization opportunities to reduce the attention computation and memory access.
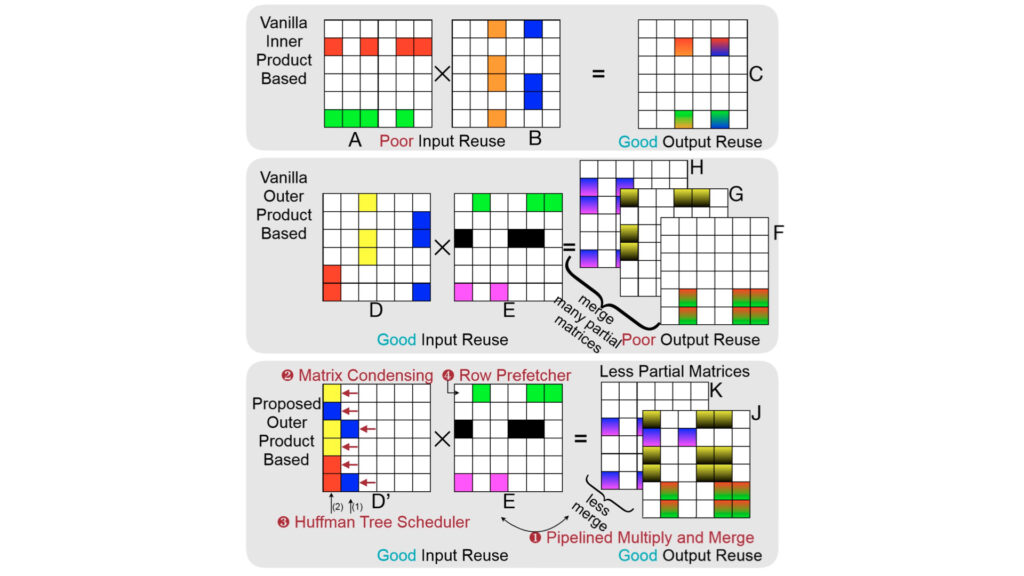
SpArch: Efficient Architecture for Sparse Matrix Multiplication HPCA’20 SpArch jointly optimizes the data locality for both input and output matrices in Generalized Sparse Matrix-Matrix Multiplication (SpGEMM) via streaming-based merger, the condensed matrix representation and the Huffman tree scheduler.
AI-Designed Hardware
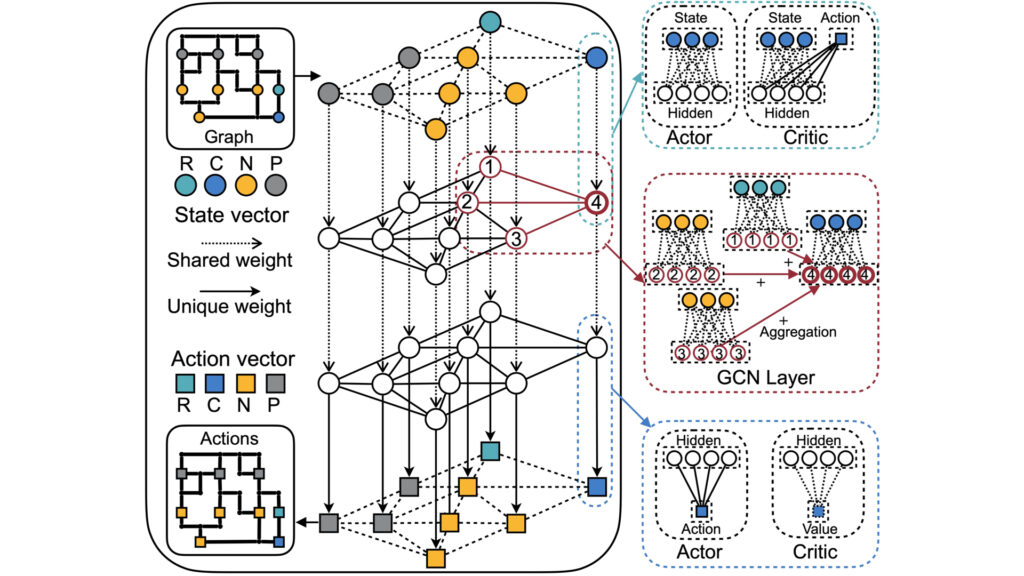
NAAS: Neural Accelerator Architecture Search DAC’21 As a data-driven approach, NAAS holistically composes highly matched accelerator and neural architectures together with efficient compiler mapping.
Quantum computing is at a historic time in its development and there is profound desire for research in quantum computer systems. With quantum system of tens or hundreds of qubits available, plenty of system level problems emerges such as compilation, qubit mapping, instruction scheduling etc. Meanwhile, the large quantum noise on real devices severely jeopardizes the reliability. Our goal is to leverage algorithm-system co-design methodology to improve noise-robust, efficiency and accuracy of quantum circuits on real quantum devices.
Quantum Computer System
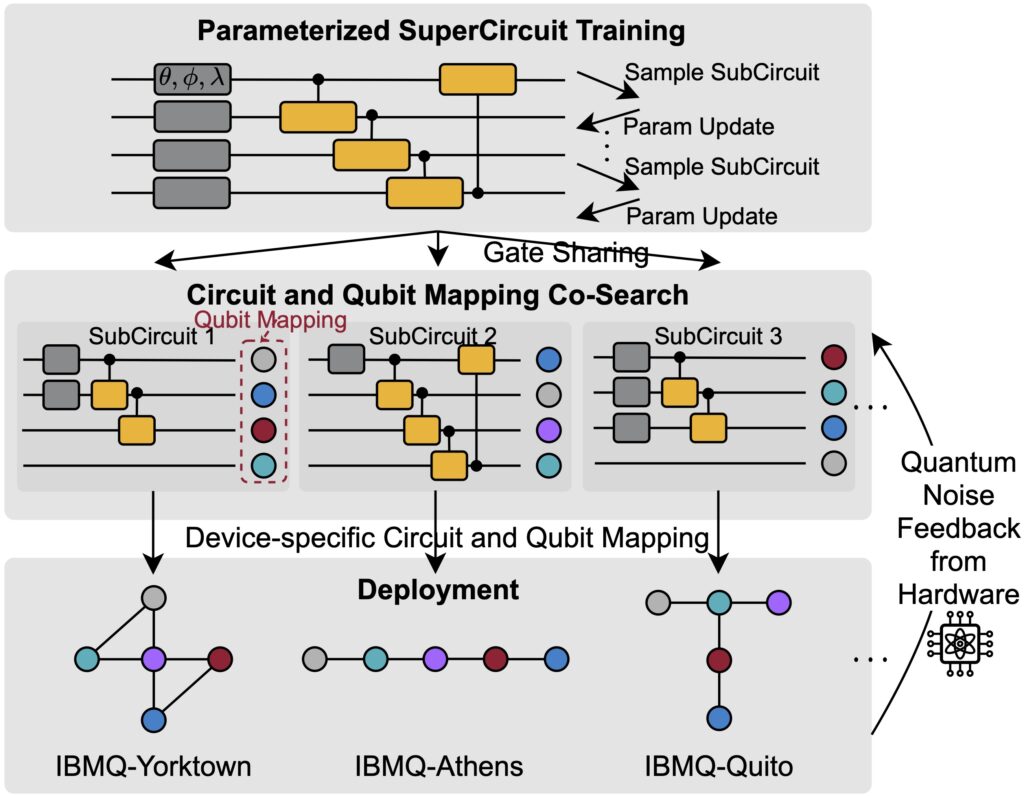
QuantumNAS: Noise-Adaptive Search for Robust Quantum Circuits HPCA’22 QuantumNAS is a framework to search for the most noise-robust parameterized quantum circuit together with its qubit mapping, with feedback from real quantum hardware. We also prune away small magnitude gates to reduce noise sources while preserving accuracy.
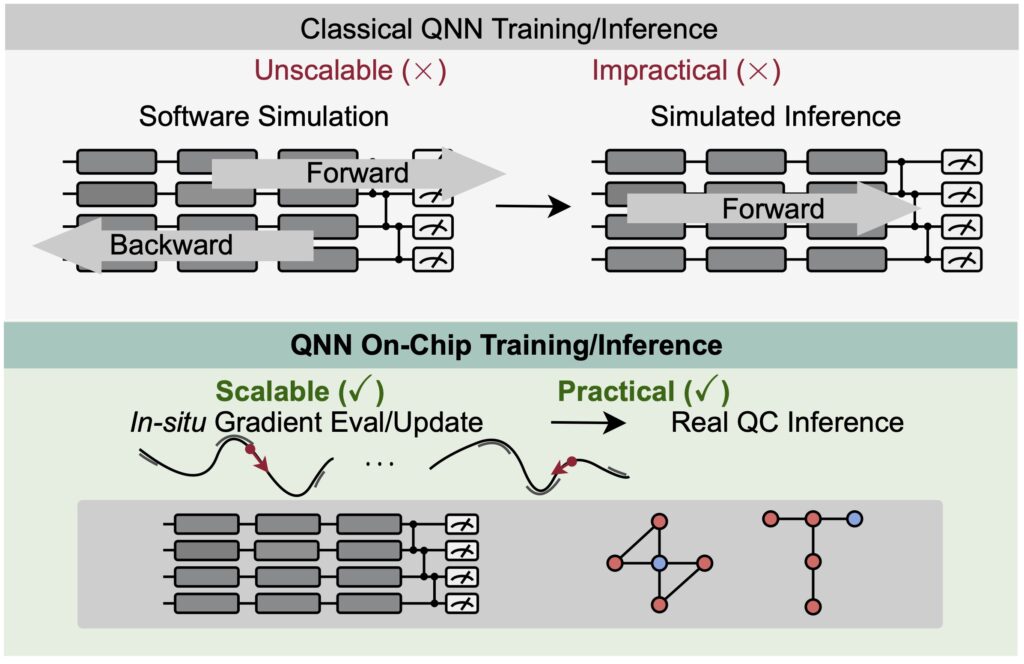
QOC: Quantum On-Chip Training with Parameter Shift and Gradient Pruning DAC’22 On-chip QNN is the first framework to train parameterized quantum circuits (quantum neural networks) using real quantum devices. The gradients are computed on quantum machines using parameter shift rules. Probabilistic gradients pruning is proposed to improve the robustness of gradients.
TorchQuantum Library HPCA’22 TorchQuantum is a library for quantum machine learning and machine learning for quantum system. It support construction of quantum neural neural networks in native PyTorch operations and faster training on GPU/CPUs. It also provides example machine learning models to optimize quantum system problem. Moreover, it supports push-the-button deployment on real quantum devices such as IBMQ quantum machines. We provide many tutorials and examples to help users get familiar with the quantum computer system area.
Designing specialized neural network architectures for different target hardware platforms and efficiency constraints is an essential step for the deployment phase of […]
Han Cai, Ligeng Zhu, Song Han Abstract Neural architecture search (NAS) has a great impact by automatically designing effective neural network architectures. However, the […]